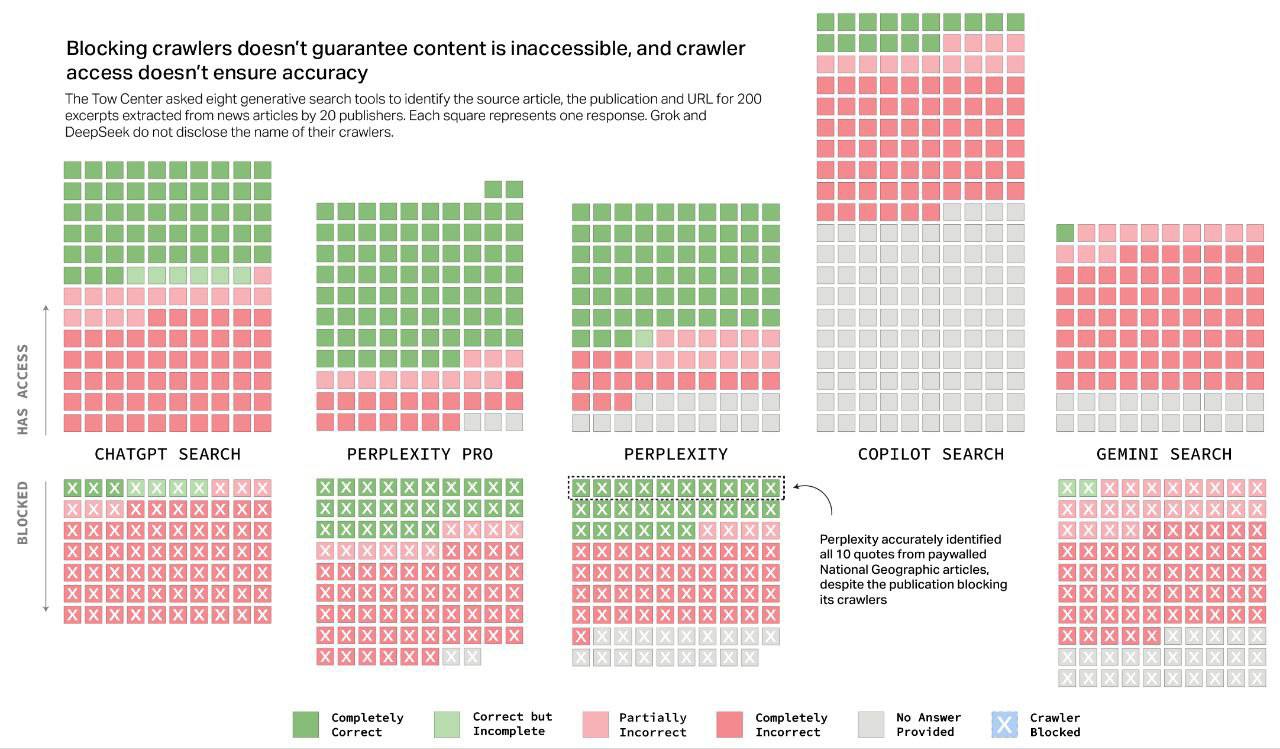
A recent study by the Tow Center for Digital Journalism at Columbia University delivered a stark reality check on the current state of AI-driven search. The findings are a critical reminder that while generative AI is advancing at an incredible pace, its reliability in retrieving and citing factual information is still deeply flawed.
The researchers tested eight leading AI search systems, including prominent models like ChatGPT and Google’s Gemini. The results demonstrate a significant gap between capability and accuracy.
The Alarming Error Rates
Across the board, the performance was poor, with most models providing incorrect answers to over 60% of the queries.
- Perplexity: Emerged as the best performer, yet still returned incorrect answers for 37% of queries.
- Grok 3 (from xAI): Had the highest error rate, failing on a staggering 94% of prompts.
- DeepSeek: Incorrectly cited its sources in 115 out of 200 test cases.
These are not minor rounding errors; they are fundamental failures in the core function of search—to provide accurate, verifiable information.
The Deeper Problem: Misinformation and Publisher Control
The issue extends beyond simple inaccuracies. The study highlights a systemic problem where AI models confidently present incorrect information, mislead users with faulty attributions, and retrieve information inconsistently. Critics rightly point out that this model removes transparency and user agency, amplifying bias and potentially delivering ungrounded or even toxic answers.
For publishers, the situation is particularly concerning. Many AI companies developing these tools have shown little interest in collaborating with news organizations. Even when they do, the systems often fail to produce accurate citations or respect publisher preferences set via the Robots Exclusion Protocol (robots.txt). This leaves publishers with few effective options to control how—or if—their content is used and surfaced by these chatbots.
A Glimmer of Hope or Wishful Thinking?
Despite the bleak results, some maintain an optimistic outlook. Mark Howard, the COO of Time, offered a perspective that resonates with anyone in tech: “Today is the worst that the product will ever be.”
He argues that the sheer scale of investment and engineering talent focused on these platforms ensures they will continuously improve. While this is likely true, it places the burden of discernment entirely on the user. Believing that these free, rapidly evolving products are 100% accurate today is a mistake.
When contacted, the AI companies mentioned in the report either didn’t respond or provided generic statements. OpenAI and Microsoft reiterated their commitment to respecting publisher preferences and improving accuracy, but did not address the specific findings of the study.
For builders and entrepreneurs in the AI space, these findings are not a deterrent but a directive. The challenge isn’t just about building more powerful models, but about instilling them with reliability, transparency, and a verifiable connection to ground truth. Until then, the promise of AI search will remain just that—a promise.
Original study reference: The Tow Center for Digital Journalism