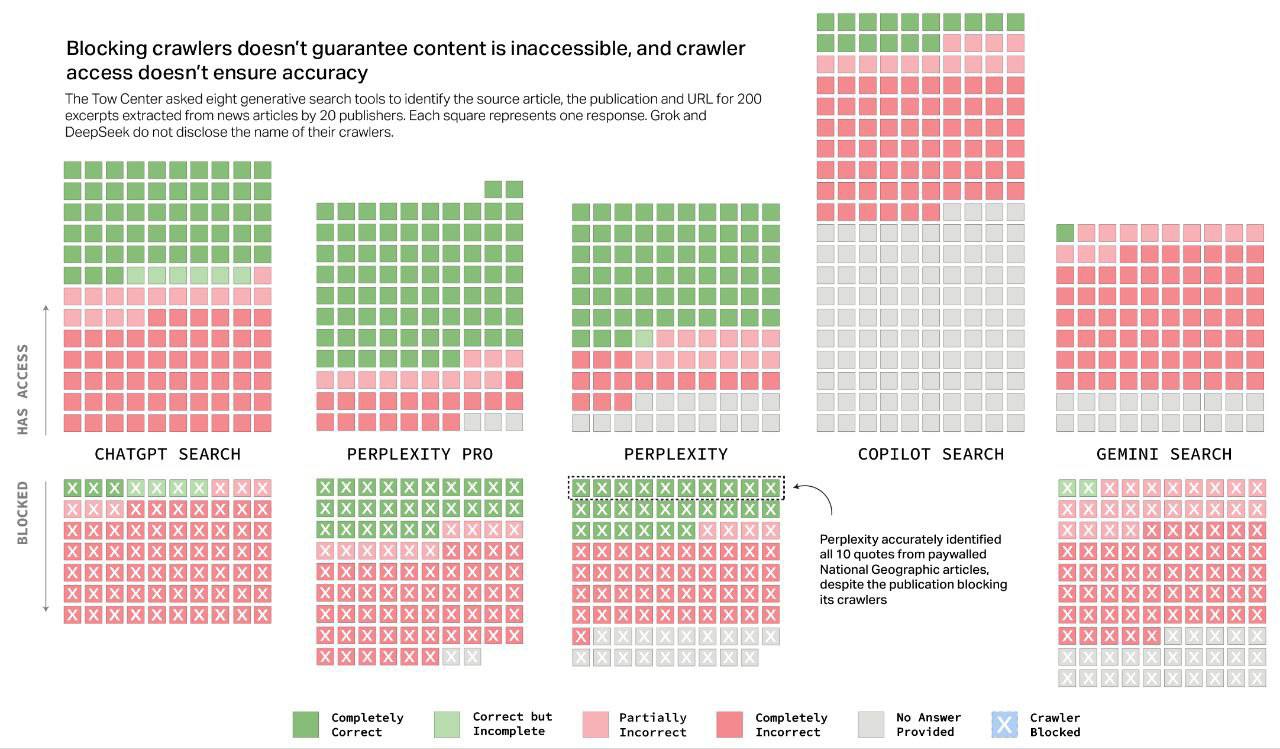
Недавнее исследование Центра цифровой журналистики Тоу при Колумбийском университете стало суровым напоминанием о текущем состоянии поиска на основе ИИ. Выводы исследования критически важны, поскольку, хотя генеративный ИИ развивается невероятными темпами, его надежность в получении и цитировании фактической информации по-прежнему глубоко несовершенна.
Исследователи протестировали восемь ведущих поисковых систем с ИИ, включая такие известные модели, как ChatGPT и Google Gemini. Результаты демонстрируют значительный разрыв между возможностями и точностью.
Тревожные показатели ошибок
В целом производительность была низкой: большинство моделей давали неверные ответы на более чем 60% запросов.
- Perplexity: Показала себя лучше всех, но все же возвращала неверные ответы в 37% запросов.
- Grok 3 (от xAI): Имела самый высокий процент ошибок, не справившись с ошеломляющими 94% запросов.
- DeepSeek: Неправильно сослалась на свои источники в 115 из 200 тестовых случаев.
Это не незначительные ошибки округления; это фундаментальные сбои в основной функции поиска — предоставлении точной, проверяемой информации.
Более глубокая проблема: дезинформация и контроль издателей
Проблема выходит за рамки простых неточностей. Исследование подчеркивает системную проблему, когда модели ИИ уверенно представляют неверную информацию, вводят пользователей в заблуждение ошибочными атрибуциями и непоследовательно извлекают информацию. Критики справедливо указывают, что эта модель устраняет прозрачность и свободу действий пользователя, усиливая предвзятость и потенциально выдавая необоснованные или даже токсичные ответы.
Для издателей ситуация особенно тревожна. Многие компании, разрабатывающие эти инструменты ИИ, мало заинтересованы в сотрудничестве с новостными организациями. Даже когда они это делают, системы часто не могут производить точные цитаты или уважать предпочтения издателей, установленные через Протокол исключения роботов (robots.txt). Это оставляет издателям мало эффективных вариантов контроля над тем, как — и используется ли — их контент этими чат-ботами.
Проблеск надежды или принятие желаемого за действительное?
Несмотря на неутешительные результаты, некоторые сохраняют оптимистичный настрой. Марк Ховард, главный операционный директор Time, высказал мнение, которое перекликается со всеми, кто работает в сфере технологий: “Сегодня продукт будет худшим, каким он когда-либо будет.”
Он утверждает, что огромные инвестиции и инженерные таланты, сосредоточенные на этих платформах, гарантируют их постоянное улучшение. Хотя это, вероятно, правда, это полностью возлагает бремя различения на пользователя. Верить, что эти бесплатные, быстро развивающиеся продукты сегодня на 100% точны, — ошибка.
При обращении к компаниям ИИ, упомянутым в отчете, они либо не ответили, либо предоставили общие заявления. OpenAI и Microsoft подтвердили свою приверженность уважению предпочтений издателей и повышению точности, но не затронули конкретные выводы исследования.
Для разработчиков и предпринимателей в сфере ИИ эти выводы являются не сдерживающим фактором, а руководством к действию. Задача состоит не только в создании более мощных моделей, но и в том, чтобы придать им надежность, прозрачность и проверяемую связь с реальными данными. До тех пор обещания ИИ-поиска останутся лишь обещанием.
Оригинальное исследование: The Tow Center for Digital Journalism